

What is Supervised Learning?
Supervised learning is a type of machine learning (a branch of AI) where computers learn from examples that already have the right answers. Imagine teaching a robot to sort fruits: you show it labeled photos—like “apple” or “banana”—so it can guess correctly on new ones. It uses these “labeled” datasets to train itself to sort info or predict what happens next.
As the computer sees new data, it tweaks its settings until it gets things right. This happens during a check called cross-validation. It’s great for big real-world problems, like spotting spam emails and sending them to a junk folder.
How Does Supervised Learning Work?
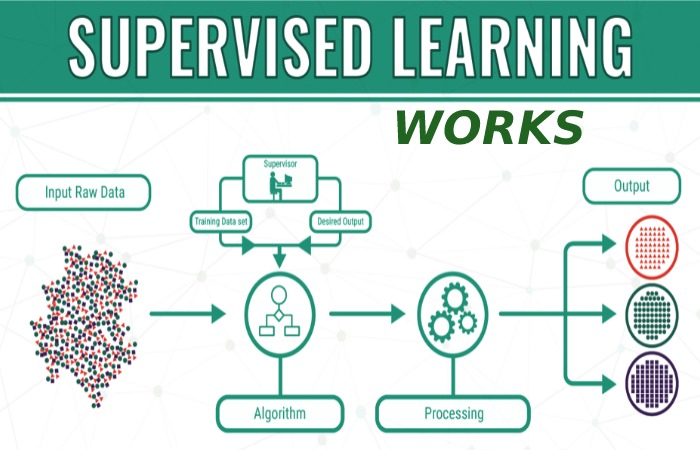
It starts with a bunch of training examples that include both the inputs (like a photo) and the correct outputs (like “that’s a cat”). The computer studies these to spot patterns and aim for the right results. It checks how good it is using a “loss function” (basically a score for mistakes) and keeps adjusting until errors are super low.
There are two main types:
Classification: This is like putting things into buckets. The computer learns to label new stuff, like deciding if an email is “spam” or “not spam.” Popular tools for this include linear classifiers, support vector machines (SVMs—like drawing lines to separate groups), decision trees (like a choose-your-own-adventure map), k-nearest neighbors (checking similar examples nearby), and random forests (a team of decision trees voting).
Regression: This predicts numbers, like guessing house prices based on size and location. It figures out how one thing affects another. Common ones are linear regression (straight-line predictions), logistic regression (for yes/no chances), and polynomial regression (curvy-line predictions).
Real-World Examples of Supervised Learning

These models power cool business tools. Here are some:
Spotting Images and Objects: Computers can find and name things in photos or videos, like tagging friends on Instagram. This helps with apps that analyze pictures.
Predicting the Future: Businesses use it to forecast sales or trends from past data. Leaders make smarter choices, like stocking more popular items.
Understanding Customer Feelings: It scans reviews or chats to pick out emotions (happy? mad?) and what people mean. This helps companies chat better with customers and build stronger brands.
Catching Spam: Train it on old emails marked “spam” or “good,” and it learns to flag the junky ones automatically.
The Tough Parts of Supervised Learning
It’s awesome for insights and automation, but not perfect. Here’s why it’s tricky:
You need experts to set it up just right.
Building the model takes a lot of time.
If the training data has mistakes (human errors happen!), the computer learns wrong.
Unlike other types, it can’t sort unlabeled stuff on its own—you have to prep everything.
Supervised vs. Unsupervised vs. Semi-Supervised Learning
People often compare these. Supervised needs labeled data to learn.
Unsupervised Learning: No labels! It looks at raw data and finds hidden patterns, like grouping similar songs into playlists. Great when you’re not sure what to look for. Tools include hierarchical clustering (building family trees of data), k-means (dividing into set groups), and Gaussian mixtures (blending groups smoothly).
Semi-Supervised Learning: A mix—some data is labeled, most isn’t. It’s cheaper and faster since labeling everything is a pain and costs money.
If labeling is too hard, unsupervised or semi-supervised might be better.
Conclusion
Supervised learning is like having a teacher guiding a student: the “supervisor” is the labeled data showing the right answers. The computer practices on these examples, then tackles new ones by matching patterns from training. Over time, it gets smart at classifying or predicting—just like you acing a test after studying!