
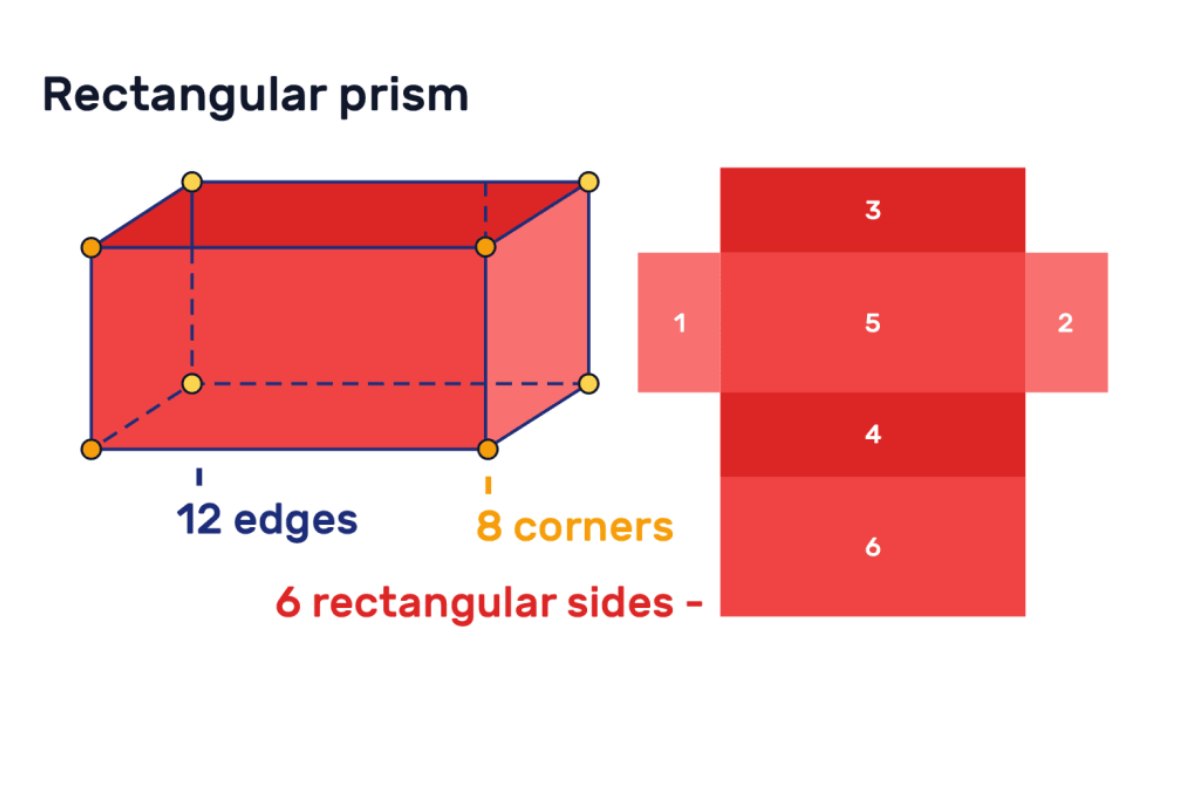
Features and properties of rectangular prism – In mathematics, there are several kinds of shapes and configurations of objects. Geometry considers being the study of all these kinds of shapes and configurations. The rectangular prism is the polyhedron that will include two congruent and parallel bases and it can also consider a type of cuboid. It will have six faces and all the faces will be in the shape of a rectangle which will make sure that there will be 12 edges in this particular shape. Because of the cross-section along with the length, it is also set to be a prism. Similar to the triangle, square and pentagonal prism this will also have a very broad surface area. The surface area of the prism is the area of its net.
The rectangular prism is a three-dimensional shape that will include six vertices and all the faces of the prism will be rectangles. Both of the bases of the rectangular prism must be a rectangle and the lateral faces will also be rectangles. This is the main reason why it is also known as a cuboid. Following are the basic features and properties of the rectangular prism:
- It will always have six rectangular faces, eight vertices and the 12 edges
- This particular shape will be having opposite faces which will be rectangles in shape
- It will be having the rectangular cross-section
- It will exactly look like a cuboid
Following are the Basic Types of a Rectangular Prism:
- Right rectangular prism: This particular prism will be the prism that will have a basic basis as rectangles. The right rectangle of a prison will be the one that will have six faces which are rectangles and all angles will be the right angles.
- Oblique rectangular prism: This will be the shape in which bases will not be perpendicular to each other. But the rectangular prism with bases. It will not align one directly above the other is known as the oblique tabular prism.
Examples of Rectangular Prism
The rectangular prism is a three-dimensional subject that will further make sure. It will be having the surface area, as well as volume and following. These are the examples as well as formulas of both of these systems:
- The volume of the rectangular prism: This particular volume is the measurement of the occupied units into a rectangular prism. It can represent by cubic units. It can also define as the number of units used to fill a rectangular prism. And the formula will belong to width into height cubic units.
- The lateral surface area of the rectangular prism: This is the sum of the surface area of all the faces without the base of the rectangular prism. This will be the surface area of any right rectangle a prism equivalent to the perimeter of the base times the height of the prism.
- The surface area of the rectangular prism: This will be the measure of how much-exposed area a particular prism will be having. This will express in square units. The surface area will be the sum of the lateral surface area and the price of the base area of the rectangular prism.
Apart from all the above-mentioned points. It is also very a great deal important for the kids to be clear about a rectangular prism net. Because the prism is its surface area of it. It will very easily show whenever the individuals will open the prism into a plane then all the sides will be visible at the same point in time. Calculation of the individual area will always reach the individuals to the total surface area. Hence, registering the kids on platforms like Cuemath is the best way of ensuring that they have a good amount of idea about the shapes as well as formulas like the volume of rectangular prism without any kind of program.